Hướng dẫn thu
thập dữ liệu trên web trong c #
Hướng dẫn thu
thập dữ liệu trên web trong c #

Hướng dẫn thu thập dữ liệu trên web trong c #
trong hướng dẫn này tôi sẽ chỉ cho bạn cách thực hiện thu thập dữ liệu web bằng c # và một số tập hợp .Net như
- HtmlAgilityPack
- Mạng
tôi đang viết hướng dẫn này sau khi xem video hướng dẫn từ @ Houssem Dellai . trong hướng dẫn tiếp theo của tôi, tôi sẽ sử dụng python để loại bỏ web
Thu thập dữ liệu trên web là gì?
Thu thập dữ liệu là quá trình nhờ các công cụ tìm kiếm thu thập thông tin về các trang web trên web trên toàn thế giới. Nó cũng có thể được sử dụng để tự động hóa các tác vụ bảo trì trên một trang Web, chẳng hạn như kiểm tra các liên kết hoặc xác nhận mã HTML
Bò về cơ bản có nghĩa là đi theo một con đường. đây là lý do tại sao nhiều nhà phát triển trang web cung cấp bản đồ trang web để dễ dàng điều hướng và thu thập dữ liệu trên trang web của họ.
Làm thế nào các công cụ tìm kiếm có thể đề xuất một vài trang trong số hàng nghìn tỷ tồn tại? Câu trả lời là thu thập dữ liệu trên web
Trình thu thập dữ liệu trên web là gì?
Trình thu thập dữ liệu web còn được gọi là trình thu thập dữ liệu web hoặc webrobot là một chương trình hoặc tập lệnh tự động duyệt thế giới Wide Web theo phương pháp tự động, có phương pháp. Quá trình này được gọi là thu thập dữ liệu Web hoặc Spidering. Nhiều trang web hợp pháp, đặc biệt là các công cụ tìm kiếm, sử dụng Spidering như một phương tiện cung cấp dữ liệu cập nhật cho các phân tích.
Trình thu thập dữ liệu web là chương trình máy tính quét web, 'đọc' mọi thứ họ tìm thấy. Trình thu thập dữ liệu web còn được gọi là nhện, bot và bộ chỉ mục tự động. Các trình thu thập thông tin này quét các trang web để xem những từ nào chúng chứa và những từ đó được sử dụng. Trình thu thập thông tin biến những phát hiện của nó thành một chỉ số khổng lồ
Mục đích của thu thập dữ liệu web thường dành cho mục đích Lập chỉ mục Web ( spidering web ).
Lập chỉ mục web
Lập chỉ mục web đề cập đến các phương pháp khác nhau để lập chỉ mục nội dung của một trang web hoặc toàn bộ Internet. Chỉ mục về cơ bản là một danh sách lớn các từ và các trang web có tính năng của chúng. Trình thu thập dữ liệu web quét web thường xuyên để chúng luôn có một chỉ mục cập nhật của web. Vì vậy, khi bạn hỏi một công cụ tìm kiếm các trang về hà mã, công cụ tìm kiếm sẽ kiểm tra chỉ mục của nó và cung cấp cho bạn một danh sách các trang có đề cập đến hà mã.
Khi Google truy cập trang web của bạn cho mục đích theo dõi. Quá trình này được thực hiện bởi trình thu thập thông tin Spider của Google và sau khi thu thập thông tin xong, kết quả sẽ được đưa vào chỉ mục của Google (tức là tìm kiếm trên web)
Một số công cụ thu thập dữ liệu trên web cho các nền tảng khác nhau
sau tất cả phần giới thiệu về việc thu thập thông tin trên web, bây giờ chúng ta hãy đi vào mã hóa thực tế bằng cách sử dụng c # và visual studio 2013 theo các bước sau. Hãy nhớ rằng trong hướng dẫn này, chúng tôi sẽ nhận được các mẫu xe, liên kết, url hình ảnh và giá cả nhưng sau khi nắm vững quy trình này, bạn có thể nhận được bất kỳ thông tin nào trên bất kỳ trang web nào miễn là chúng có sẵn trên trang web nhưng nếu bạn có bất kỳ thách thức nào bạn có thể tiếp cận tôi để chúng ta có thể nhìn vào cùng nhau.
- Khởi động studio hình ảnh của bạn
2. Tạo dự án mới
nhấp vào dự án mới để tạo dự án mới, chọn Ứng dụng bảng điều khiển và đặt tên là CrawlerDemo sau đó nhấn ok

3. sau khi tạo dự án, hãy thêm các tham chiếu HtmlAgilityPack và Net.Http vào dự án bằng cách nhấp chuột phải vào tên dự án trong trình khám phá giải pháp và sau đó chọn Manage Nuget Gói sau đó nhập HtmlAgilityPack vào hộp tìm kiếm sau đó nhấp vào cài đặt. Lặp lại quy trình tương tự cho Net.Http
Lưu ý: vui lòng đảm bảo rằng bạn đã kết nối với internet và cũng là nhà thám hiểm Giải pháp của bạn sẽ không có lớp Xe hơi, chúng tôi sẽ tạo ra điều đó sau, đây chỉ là cách bạn khám phá Giải pháp sẽ như thế nào ở cuối hướng dẫn, vì vậy hãy kiên nhẫn


4. sau khi thêm các tham chiếu đến dự án của chúng tôi, chúng ta hãy nhập chúng vào dự án bằng cách thêm
- sử dụng HtmlAgilityPack;
- sử dụng System.Net.Http;
Vì vậy, dự án của chúng tôi nên giống với hình ảnh dưới đây

hãy để chúng tôi tạo một phương thức async và đặt tên là startCrawlerasync ()

tiếp theo, chúng tôi tạo một biến cho url trang web và cũng là một phiên bản của httpClient để giữ url trang web và cũng là một htmldocument để có quyền truy cập vào các phần tử và thẻ html khác nhau trên trang web
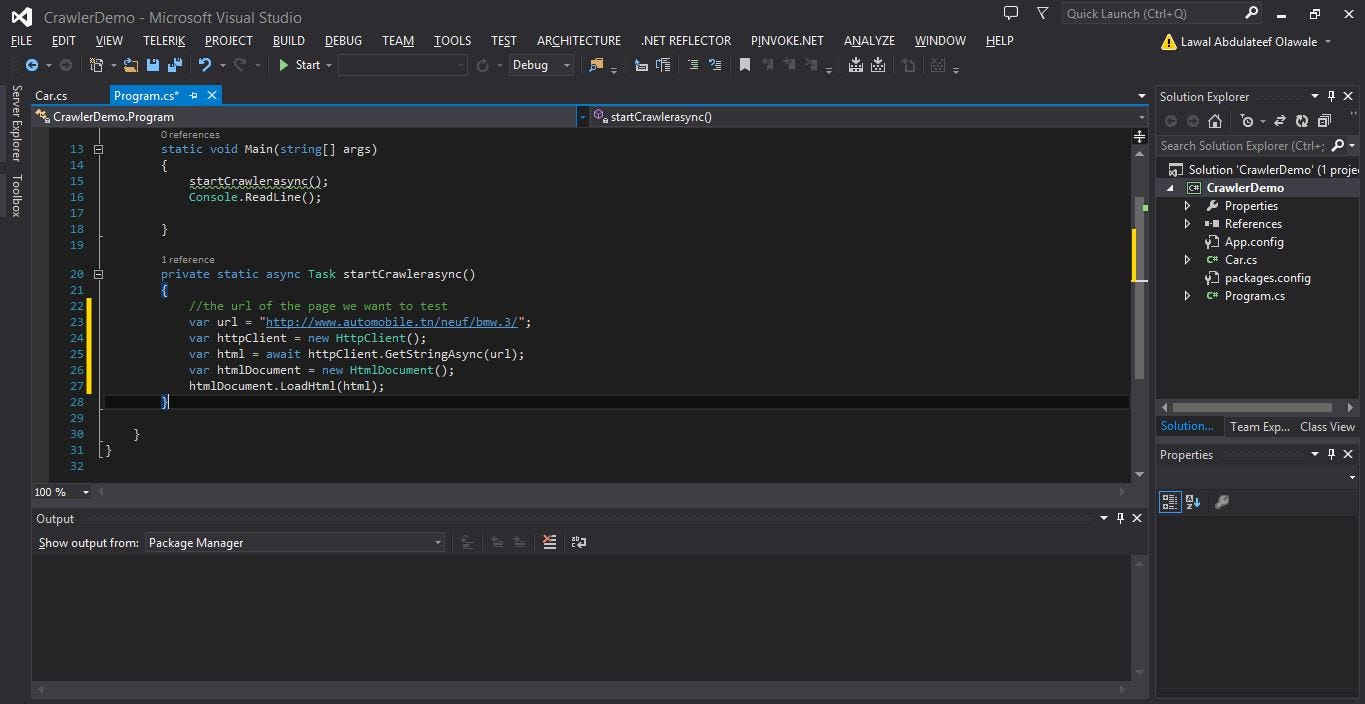
hãy nhớ rằng trang web chúng tôi muốn thực hiện thu thập thông tin trên web là

Nếu bạn nhấp chuột phải vào trang để kiểm tra trang sẽ có chế độ xem tương tự như hình ảnh bên dưới

tiếp theo, chúng tôi sẽ khai báo một biến gọi là div để lưu trữ phần tử div vì tất cả các phần tử và thẻ khác mang thông tin phương tiện cho hướng dẫn được nhúng bên trong phần tử div với tên lớp là article articleewew_car article_last_modele

tiếp theo chúng ta hãy tạo một lớp gọi là Xe với các thuộc tính sau;
Mô hình
Giá bán
Liên kết
URL hình ảnh
Nếu bạn không biết cách tạo một lớp, chỉ cần vào dự án trong trình khám phá giải pháp và sau đó chọn thêm lớp chọn sau đó đặt tên cho nó Xe rồi nhấn add

Sau khi thêm lớp Xe, nhấp vào nó để mở nếu nó không mở để mã hóa, sau đó thêm các thuộc tính trên vào nó. nên trông giống như thế này

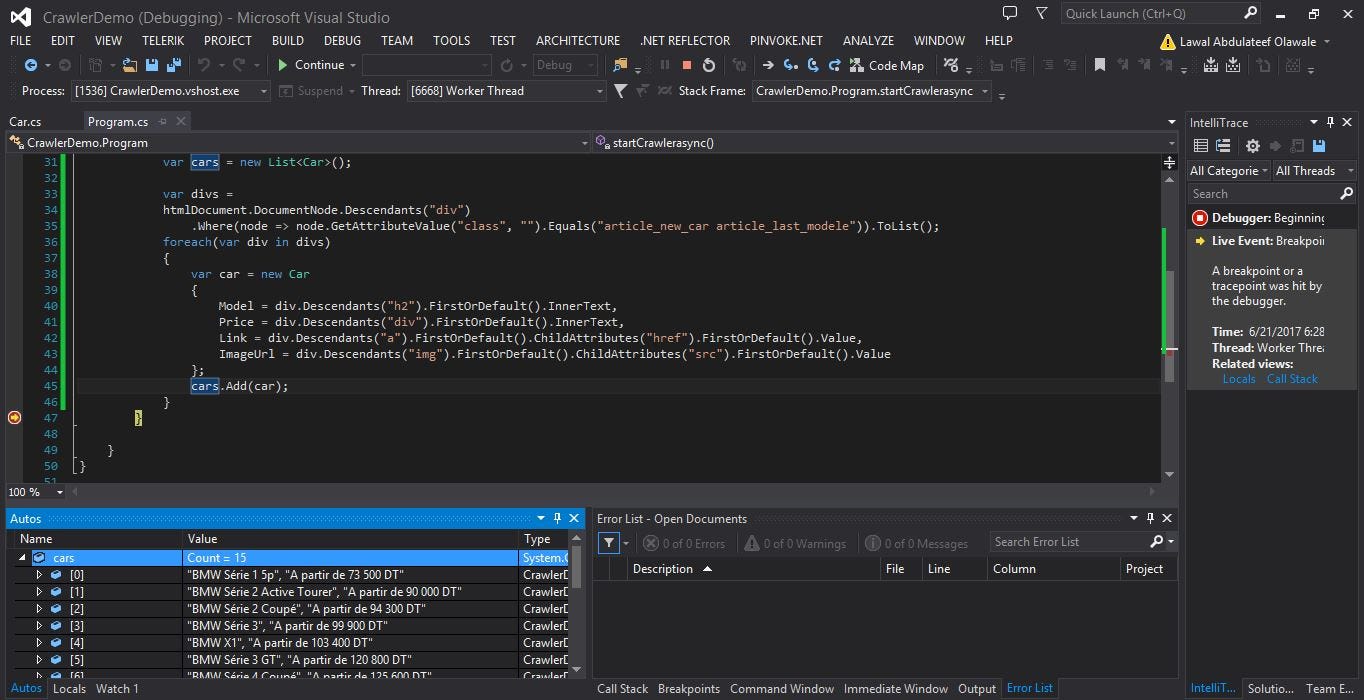
sau đó điều hướng trở lại chương trình chính để tiếp tục, chúng ta sẽ cần thêm câu lệnh foreach để lặp lại các giá trị và phần tử trong biến div

lưu ý rằng Mô hình của xe nằm trong phần tử h2, giá nằm trong phần tử div, liên kết đến xe nằm trong thẻ neo và Imageurl nằm trong thẻ img.
tiếp theo, chúng tôi sẽ tạo một danh sách và chuyển lớp Xe thành loại để chứa tất cả thông tin được thu thập.

Tiếp theo, chúng tôi sẽ tạm dừng dự án tại điểm được hiển thị bên dưới, sau đó nhấp vào chạy sau đó di chuột vào biến ô tô và sau đó thu gọn nó để xem các mô hình và giá khác nhau. thông tin khác cũng có sẵn bên trong biến Cars nhưng vì chúng tôi đã cấu hình debuggerDisplay để hiển thị mô hình và giá cả cạnh nhau
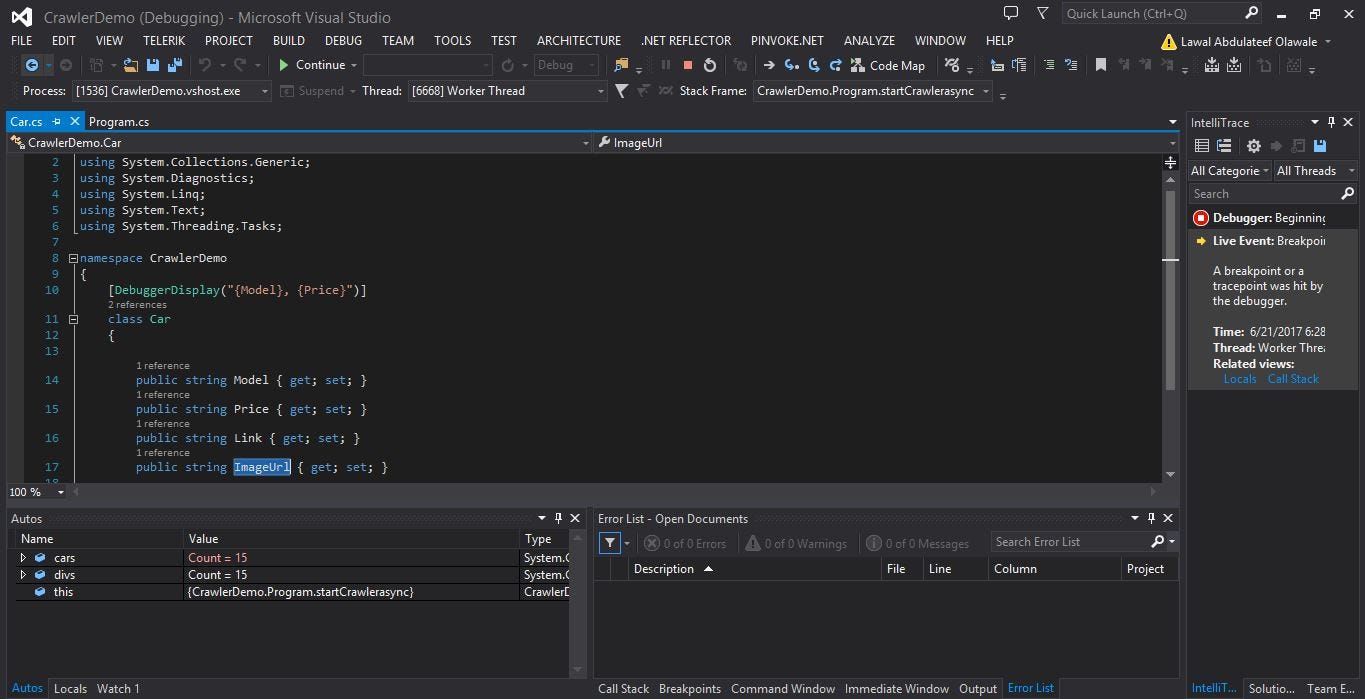
hãy để chúng tôi tạm dừng và chạy mã
Tiếng hoan hô! làm thế nào mã làm việc như dự định
Chúc mừng mã hóa !!!
tôi muốn nâng cao mã bằng cách thêm thông tin vào cơ sở dữ liệu để lưu trữ chúng trong trường hợp cần cho mục đích tương lai
- đầu tiên chúng ta hãy tạo cấu trúc cơ sở dữ liệu của chúng tôi như dưới đây

2. sau đó thêm dòng mã sau vào dự án như hình dưới đây


sau khi chạy ứng dụng và nhấn phím enter để thoát khỏi ứng dụng, cơ sở dữ liệu của bạn sẽ được cập nhật như hình dưới đây
Cảm ơn bạn đã dành thời gian để đọc bài viết này,
Tôi hy vọng nó là hữu ích?
tôi <mã hóa />
bạn có thể tải xuống mã đầy đủ từ tài khoản git của tôi