IronWebscraper là một Thư viện .Net để quét web, trích xuất dữ liệu web và phân tích nội dung web. Đây là một thư viện dễ sử dụng có thể được thêm vào các dự án Microsoft Visual Studio để sử dụng trong phát triển và sản xuất.
IronWebscraper có nhiều tính năng và khả năng độc đáo như kiểm soát các trang, đối tượng, phương tiện được phép và bị cấm, v.v. Nó cũng cho phép quản lý nhiều danh tính, bộ đệm web và nhiều tính năng khác mà chúng tôi sẽ thảo luận trong tài liệu hướng dẫn này.
Khán giả mục tiêu
Hướng dẫn này nhắm đến các nhà phát triển phần mềm với các kỹ năng lập trình cơ bản hoặc nâng cao, những người muốn xây dựng và triển khai các giải pháp cho khả năng cạo nâng cao (quét trang web, thu thập và trích xuất dữ liệu trang web, phân tích nội dung trang web, thu hoạch web).
Kỹ năng cần có
Các nguyên tắc cơ bản cơ bản của lập trình với các kỹ năng sử dụng một trong các ngôn ngữ Lập trình Microsoft như C # hoặc VB.NET
Hiểu biết cơ bản về Công nghệ web (HTML, JavaScript, JQuery, CSS, v.v.) và cách chúng hoạt động
Kiến thức cơ bản về Bộ chọn DOM, XPath, HTML và CSS
Công cụ
Microsoft Visual Studio 2010 trở lên
Tiện ích mở rộng dành cho nhà phát triển web dành cho trình duyệt, chẳng hạn như trình kiểm tra web cho Chrome hoặc Fireorms cho Firefox
Tại sao phải cạo? (Lý do và khái niệm)
Nếu bạn muốn xây dựng một sản phẩm hoặc giải pháp có khả năng:
Trích xuất dữ liệu trang web
So sánh nội dung, giá cả, tính năng, vv từ nhiều trang web
Quét và lưu trữ nội dung trang web
Nếu bạn có một hoặc nhiều lý do từ những điều trên, thì IronWebscraper là một thư viện tuyệt vời để phù hợp với nhu cầu của bạn
Làm thế nào để cài đặt IronWebScraper?
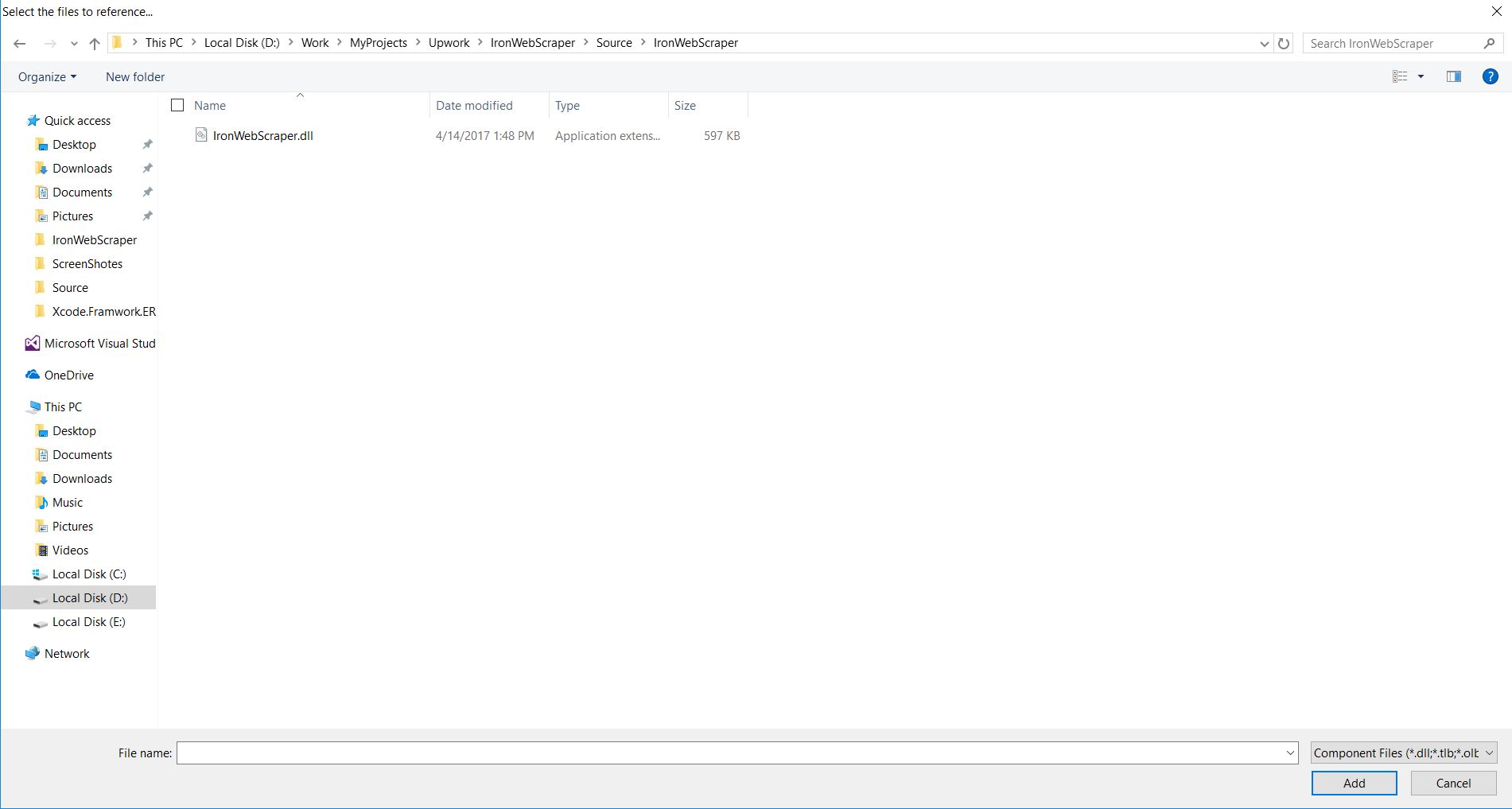
Sau khi bạn tạo một dự án mới (Xem Phụ lục A), bạn có thể thêm thư viện IronWebScraper vào dự án của mình bằng cách tự động chèn thư viện bằng NuGet hoặc cài đặt DLL thủ công.
Cài đặt bằng NuGet
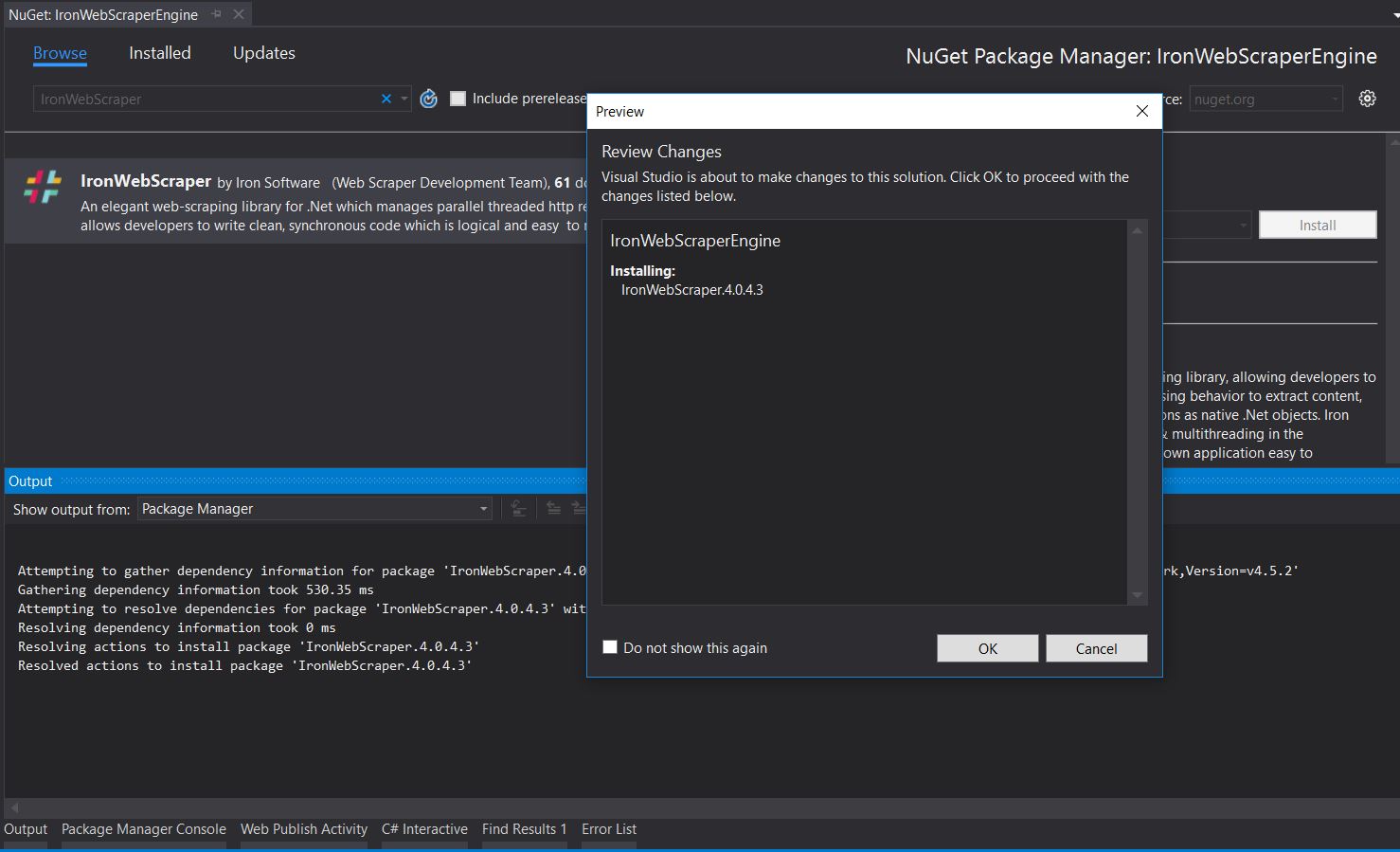
Để thêm thư viện IronWebScraper vào dự án của chúng tôi bằng NuGet, chúng tôi có thể thực hiện bằng giao diện trực quan (Trình quản lý gói NuGet) hoặc bằng lệnh bằng Bảng điều khiển quản lý gói.
Sử dụng Trình quản lý gói NuGet
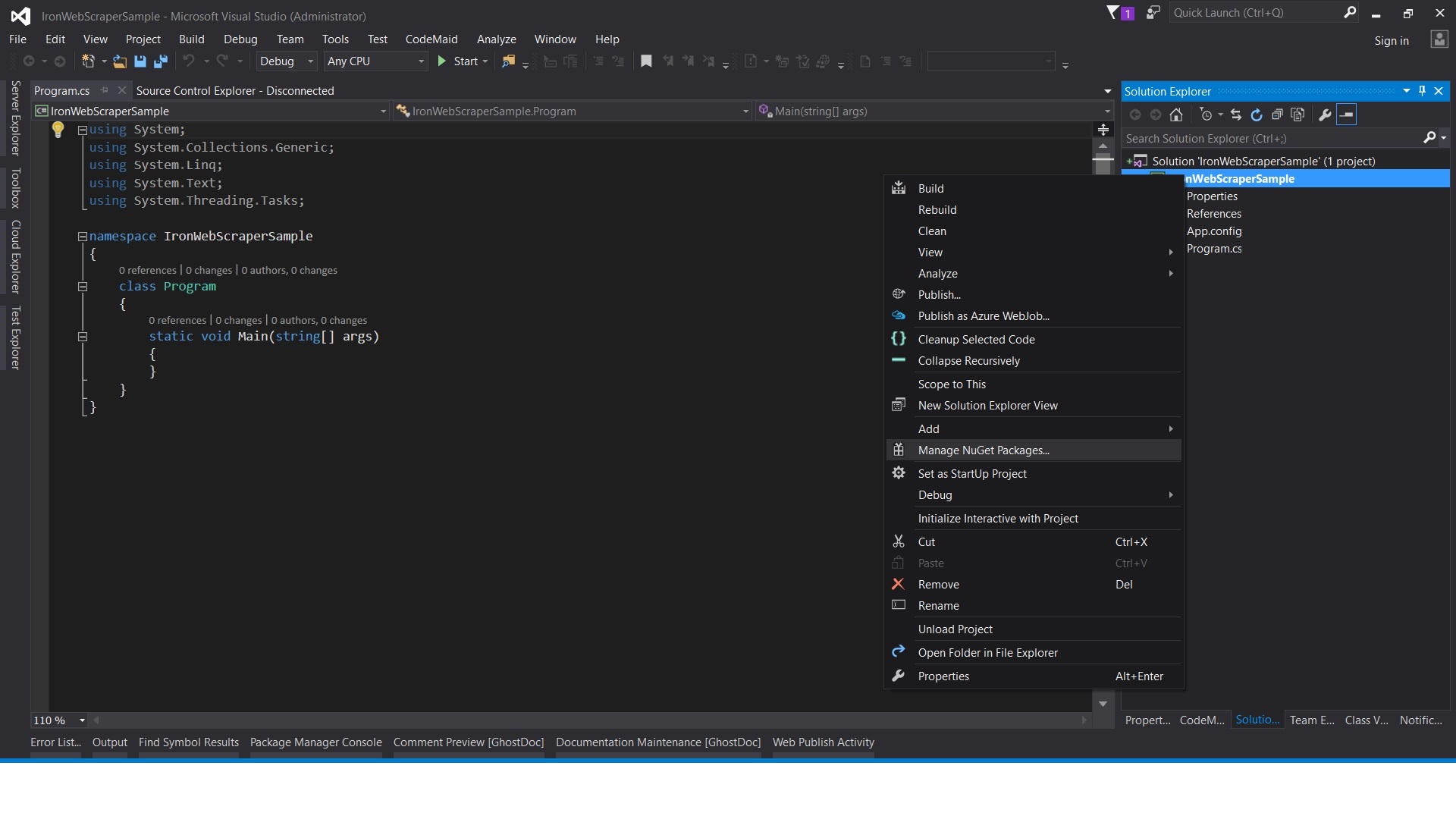
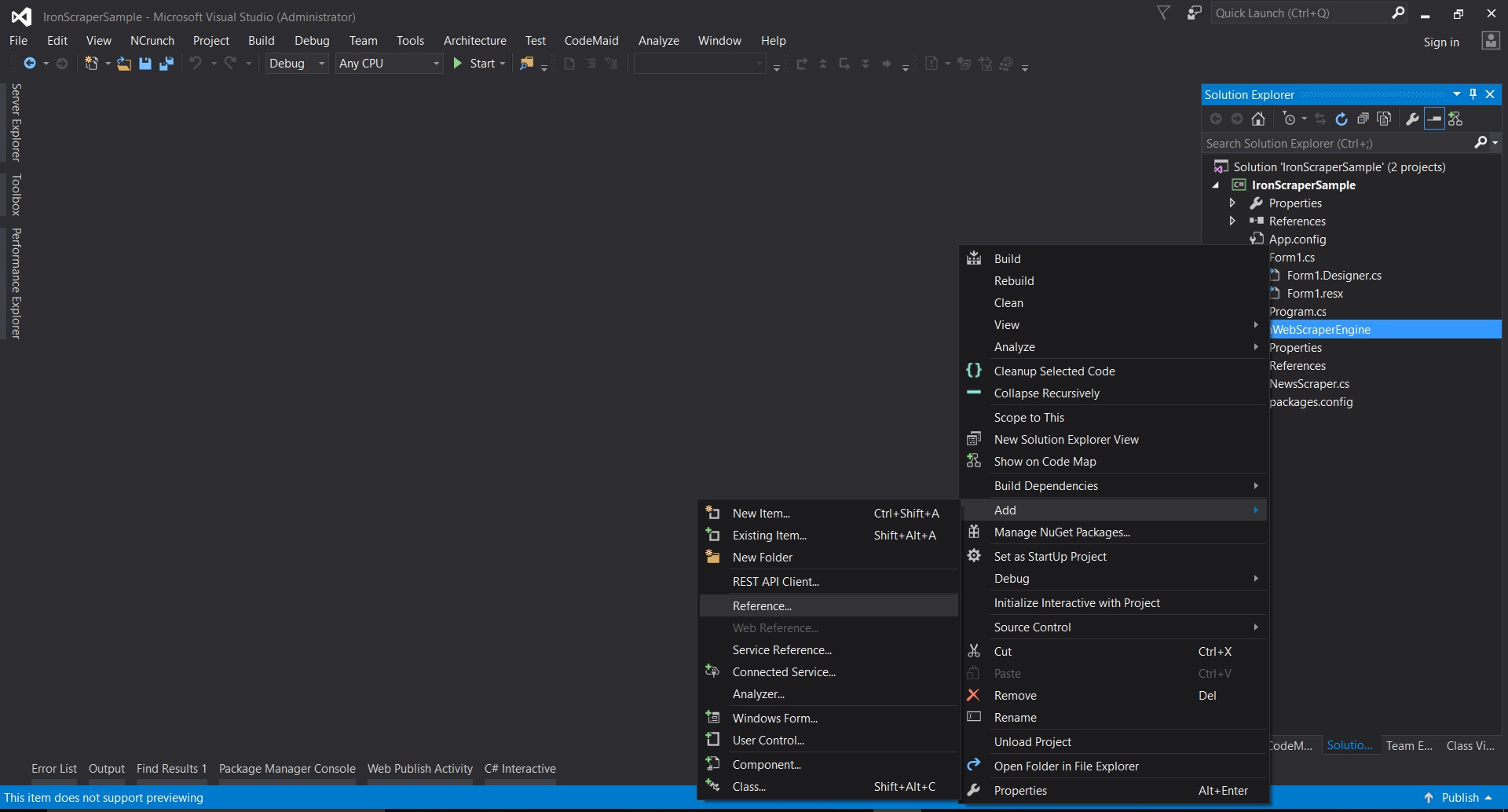
Sử dụng chuột -> nhấp chuột phải vào tên dự án -> Chọn quản lý Gói NuGet
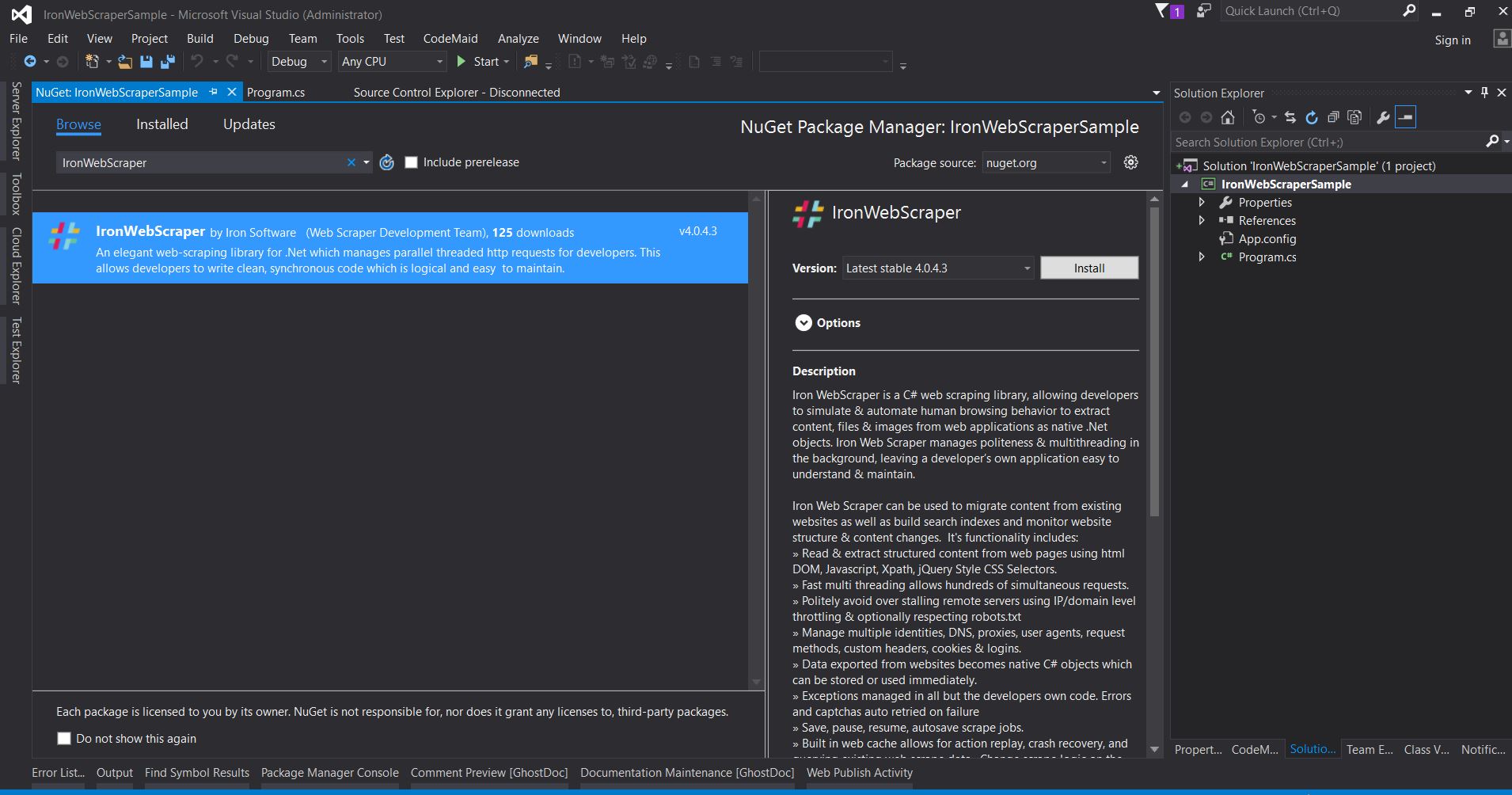
Từ tab lông mày -> tìm kiếm IronWebScraper -> Cài đặt
Nhấp vào Ok
Và chúng ta đã xong
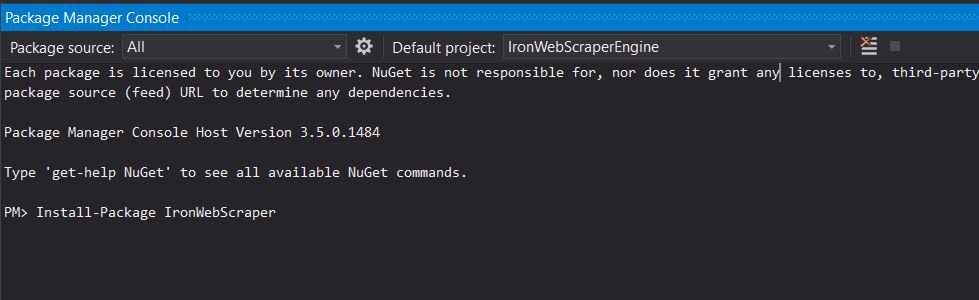
Sử dụng Bảng điều khiển gói NuGet
Từ các công cụ -> Trình quản lý gói NuGet -> Bảng điều khiển quản lý gói
Kết quả sẽ được lưu trong một tệp có định dạng WebSraper.WorkingDirecty / classname.Json
Tổng quan về mã
Scrape.Start () => kích hoạt logic scrape như sau:
Gọi phương thức init () trước tiên để bắt đầu các biến, thuộc tính cạo và thuộc tính hành vi.,
Như chúng ta có thể thấy nó đặt trang bắt đầu thành Yêu cầu ("https://blog.scrapinghub.com ", Parse) và Parse (Phản hồi phản hồi) được xác định là quá trình được sử dụng để phân tích phản hồi.
Quản lý trang web song song: http và chủ đề, giữ cho tất cả mã của bạn dễ dàng gỡ lỗi và đồng bộ.
Phương thức phân tích bắt đầu sau init () để phân tích trang.
Bạn có thể tìm thấy các phần tử bằng cách sử dụng (bộ chọn Css, Js DOM, XPath)
Các phần tử được chọn được chuyển sang loại ScrapedData, bạn có thể chuyển chúng sang bất kỳ Lớp tùy chỉnh nào như (Sản phẩm, Nhân viên, Tin tức, v.v.)
Các đối tượng được lưu trong một tệp có Định dạng Json trong Thư mục (Thùng bin / Scrape / Lần). Hoặc bạn có thể đặt đường dẫn của tệp làm tham số như chúng ta sẽ thấy sau trong các ví dụ khác.
Các tùy chọn và chức năng của Thư viện IronWebScraper
Bạn có thể tìm thấy tài liệu cập nhật bên trong tệp zip đã được tải xuống bằng phương pháp cài đặt thủ công (Tập tin IronWebScifier Documentation.chm)
Để bắt đầu sử dụng IronWebscraper trong dự án của bạn, bạn phải kế thừa từ lớp (IronWebScraper.WebScraper) mở rộng thư viện lớp của bạn và thêm chức năng cạo cho nó.
Ngoài ra, bạn phải triển khai các phương thức {init (), Parse (Phản hồi phản hồi)}.
namespace IronWebScraperEngine
{
publicclassNewsScraper:IronWebScraper.WebScraper
{
publicoverridevoidInit()
{
thrownewNotImplementedException();
}
publicoverridevoidParse(Response response)
{
thrownewNotImplementedException();
}
}
}
Thuộc tính \ chức năng
Kiểu
Sự miêu tả
Trong đó ()
phương pháp
được sử dụng để thiết lập cạp
Phân tích cú pháp (Phản hồi)
phương pháp
Được sử dụng để thực hiện logic mà bộ cạp sẽ sử dụng và cách nó sẽ xử lý nó. Bảng sắp tới chứa danh sách các phương thức và thuộc tính mà Thư viện IronWebScraper đang cung cấp LƯU Ý: Có thể triển khai nhiều phương thức cho các hành vi hoặc cấu trúc trang khác nhau
BnedUrls
Được phép
Tên miền bị cấm
Bộ sưu tập
Được sử dụng để cấm / Cho phép / URL và / hoặc Tên miền Ex: BnedUrls.Add ("* .zip", "* .exe", "* .gz", "* .pdf"); Chú thích:
Một danh sách của httpIdentity () sẽ được sử dụng để tìm nạp tài nguyên web.
Mỗi danh tính có thể có một địa chỉ IP proxy khác nhau, Tác nhân người dùng, tiêu đề http, cookie liên tục, tên người dùng và mật khẩu. Cách thực hành tốt nhất là tạo Danh tính trong Phương thức WebScraper.Init của bạn và Thêm chúng vào Danh sách WebScraper.Identities này.
Thư mục làm việc
chuỗi
Thiết lập thư mục làm việc sẽ được sử dụng cho tất cả các dữ liệu liên quan đến scrape sẽ được lưu trữ vào đĩa.
Các mẫu và thực hành trong thế giới thực
Quét một trang web phim trực tuyến
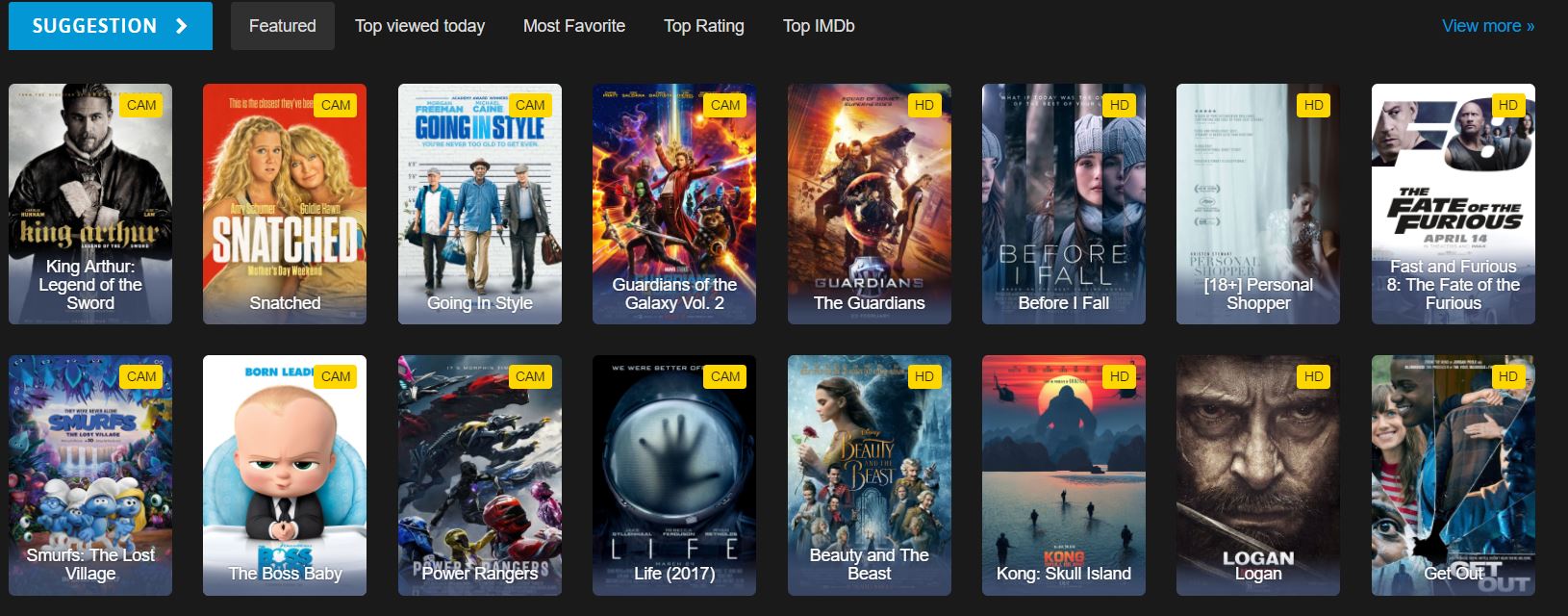
Hãy bắt đầu một ví dụ khác từ một trang web thế giới thực. Chúng tôi sẽ chọn để cạo một trang web phim.
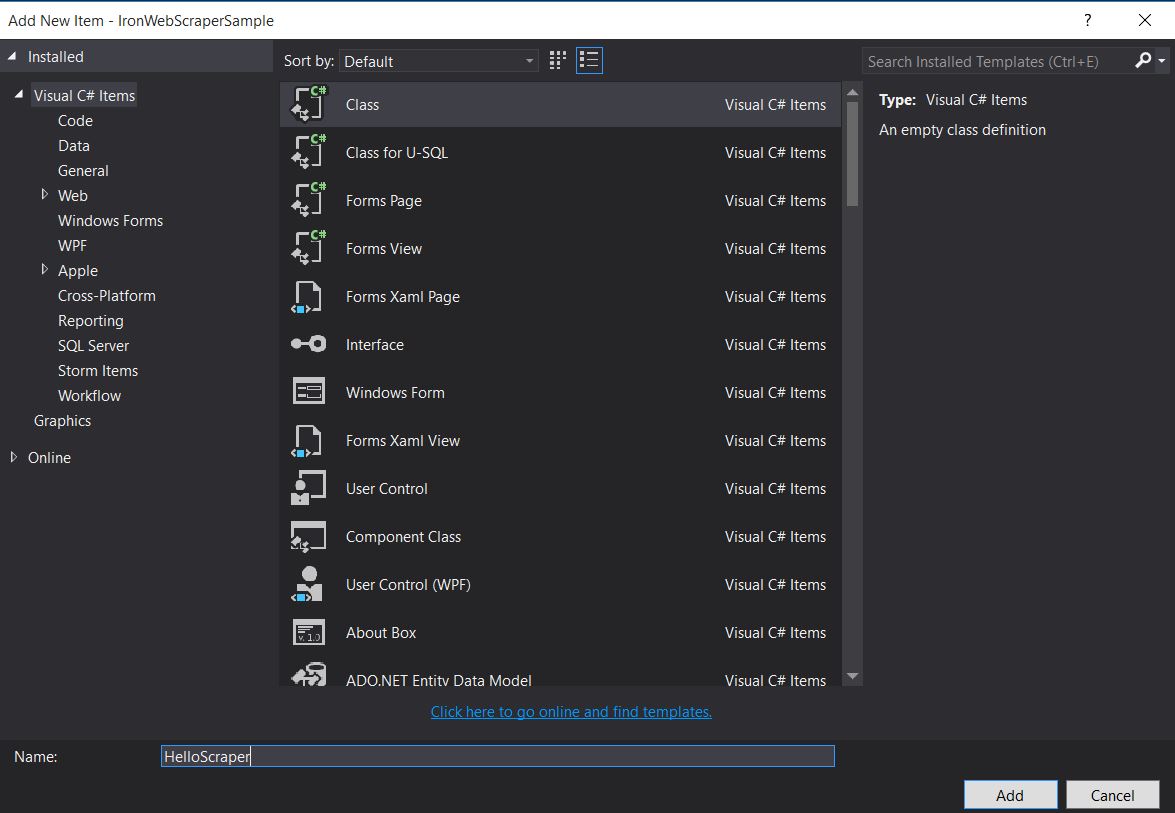
Chúng ta hãy thêm một lớp mới và đặt tên nó là Phim MovieScetter ':
Bây giờ chúng ta hãy xem trên trang web mà chúng tôi sẽ cạo:
Đây là một phần của HTML trang chủ mà chúng tôi thấy trên trang web:
<divid="movie-featured"class="movies-list movies-list-full tab-pane in fade active">
Chúng tôi triển khai Lớp phim để giữ dữ liệu bị loại bỏ
Chúng tôi chuyển các đối tượng phim cho Phương thức Scrape và nó hiểu định dạng của chúng tôi và lưu ở định dạng được xác định như chúng ta có thể thấy ở đây:
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
Chúng tôi có thể mở rộng lớp phim của mình với các thuộc tính mới (Mô tả, Thể loại, Diễn viên, Đạo diễn, Quốc gia, Thời lượng, Điểm IMDB) nhưng chúng tôi sẽ chỉ sử dụng (Mô tả, Thể loại, Diễn viên) cho mẫu của chúng tôi.
publicclassMovie
{
publicintId{get;set;}
publicstringTitle{get;set;}
publicstring URL {get;set;}
publicstringDescription{get;set;}
publicList<string>Genre{get;set;}
publicList<string>Actor{get;set;}
}
Bây giờ chúng tôi sẽ điều hướng đến trang Chi tiết để cạo nó.
IronWebScraper cho phép bạn thêm nhiều hơn vào chức năng cạo để cạo các loại định dạng trang khác nhau
Một số hệ thống trang web yêu cầu người dùng phải đăng nhập để xem nội dung; trong trường hợp này, chúng ta có thể sử dụng một HTTPIdentity: -
HttpIdentity id =newHttpIdentity();
id.NetworkUsername="username";
id.NetworkPassword="pwd";
Identities.Add(id);
Một trong những tính năng ấn tượng và mạnh mẽ nhất trong IronWebScraper, là khả năng sử dụng hàng ngàn thông tin độc đáo (thông tin người dùng và / hoặc công cụ trình duyệt) để giả mạo hoặc cạo trang web bằng nhiều phiên đăng nhập.
var proxies ="IP-Proxy1: 8080,IP-Proxy2: 8081".Split(',');
foreach(var UA inIronWebScraper.CommonUserAgents.ChromeDesktopUserAgents)
{
foreach(var proxy in proxies)
{
Identities.Add(newHttpIdentity()
{
UserAgent= UA,
UseCookies=true,
Proxy= proxy
});
}
}
this.Request("http://www.Website.com",Parse);
}
Bạn có nhiều thuộc tính để cung cấp cho bạn các hành vi khác nhau, do đó, ngăn chặn các trang web chặn bạn.
Một số thuộc tính sau: -
NetworkDomain : Tên miền mạng được sử dụng để xác thực người dùng. Hỗ trợ các mạng Windows, NTLM, Keroberos, Linux, BSD và Mac OS X. Phải được sử dụng với (NetworkUsername và NetworkPassword)
NetworkUsername : Tên người dùng mạng / http sẽ được sử dụng để xác thực người dùng. Hỗ trợ các mạng http, Windows, NTLM, Kerberos, Linux, mạng BSD và Mac OS.
NetworkPassword : Mật khẩu mạng / http được sử dụng để xác thực người dùng. Hỗ trợ các mạng http, Windows, NTLM, Keroberos, Linux, mạng BSD và Mac OS.
Proxy : để đặt cài đặt proxy
UserAgent : để đặt công cụ trình duyệt (máy tính để bàn chrome, điện thoại di động chrome, máy tính bảng chrome, IE và Firefox, v.v.)
HttpRequestHeaders : cho các giá trị tiêu đề tùy chỉnh sẽ được sử dụng với danh tính này và nó chấp nhận đối tượng từ điển (Từ điển <chuỗi, chuỗi>)
UseCookies : bật / tắt bằng cookie
IronWebScraper chạy cạp bằng cách sử dụng danh tính ngẫu nhiên. Nếu chúng ta cần xác định việc sử dụng một danh tính cụ thể để phân tích một trang, chúng ta có thể làm như vậy.
Tính năng này được sử dụng để lưu các trang được yêu cầu. Nó thường được sử dụng trong các giai đoạn phát triển và thử nghiệm; cho phép các nhà phát triển lưu trữ các trang cần thiết để sử dụng lại sau khi cập nhật mã. Điều này cho phép bạn thực thi mã của mình trên các trang được lưu trong bộ nhớ cache sau khi khởi động lại bộ quét Web và không cần kết nối với trang web trực tiếp mỗi lần (phát lại hành động).
Bạn có thể sử dụng nó trong Phương thức init ()
EnableWebCache ();
HOẶC LÀ
EnableWebCache (Hết hạn Timespan);
Nó sẽ lưu dữ liệu được lưu trong bộ nhớ cache của bạn vào thư mục WebCache trong thư mục thư mục làm việc
IronWebScraper cũng có các tính năng cho phép công cụ của bạn tiếp tục quét sau khi khởi động lại mã bằng cách đặt tên quy trình khởi động động cơ bằng cách sử dụng Bắt đầu (CrawlID)
staticvoidMain(string[] args)
{
// Create Object From Scraper class
EngineScraper scrape =newEngineScraper();
// Start Scraping
scrape.Start("enginestate");
}
Yêu cầu thực hiện và phản hồi sẽ được lưu trong thư mục SavingState bên trong thư mục làm việc.
Điều tiết
Chúng tôi có thể kiểm soát số lượng kết nối tối thiểu và tối đa và tốc độ kết nối cho mỗi tên miền.
// Gets or sets the allowed number of concurrent HTTP requests (threads) per hostname
// or IP address. This helps protect hosts against too many requests.
this.OpenConnectionLimitPerHost=25;
this.ObeyRobotsDotTxt=false;
// Makes the WebSraper intelligently throttle requests not only by hostname, but
// also by host servers' IP addresses. This is polite in-case multiple scraped domains
// are hosted on the same machine.
this.ThrottleMode=Throttle.ByDomainHostName;
this.Request("https://www.Website.com",Parse);
}
Đặc tính tiết lưu
MaxHttpConnectionLimit tổng số yêu cầu (luồng) mở được phép
RateLimitPerhost trì hoãn hoặc tạm dừng lịch sự tối thiểu (tính bằng mili giây) giữa yêu cầu đến một tên miền hoặc địa chỉ IP nhất định
OpenConnectionLimitPerhost cho phép số lượng yêu cầu HTTP đồng thời (luồng)
ThrottleMode Làm cho WebSraper yêu cầu một cách thông minh ga không chỉ bởi tên máy, mà còn bởi địa chỉ IP máy chủ lưu trữ. Đây là lịch sự trong trường hợp nhiều tên miền bị loại bỏ được lưu trữ trên cùng một máy.
ruột thừa
Làm thế nào để tạo một ứng dụng Windows Form?
Chúng ta nên sử dụng Visual Studio 2013 hoặc cao hơn cho việc này.
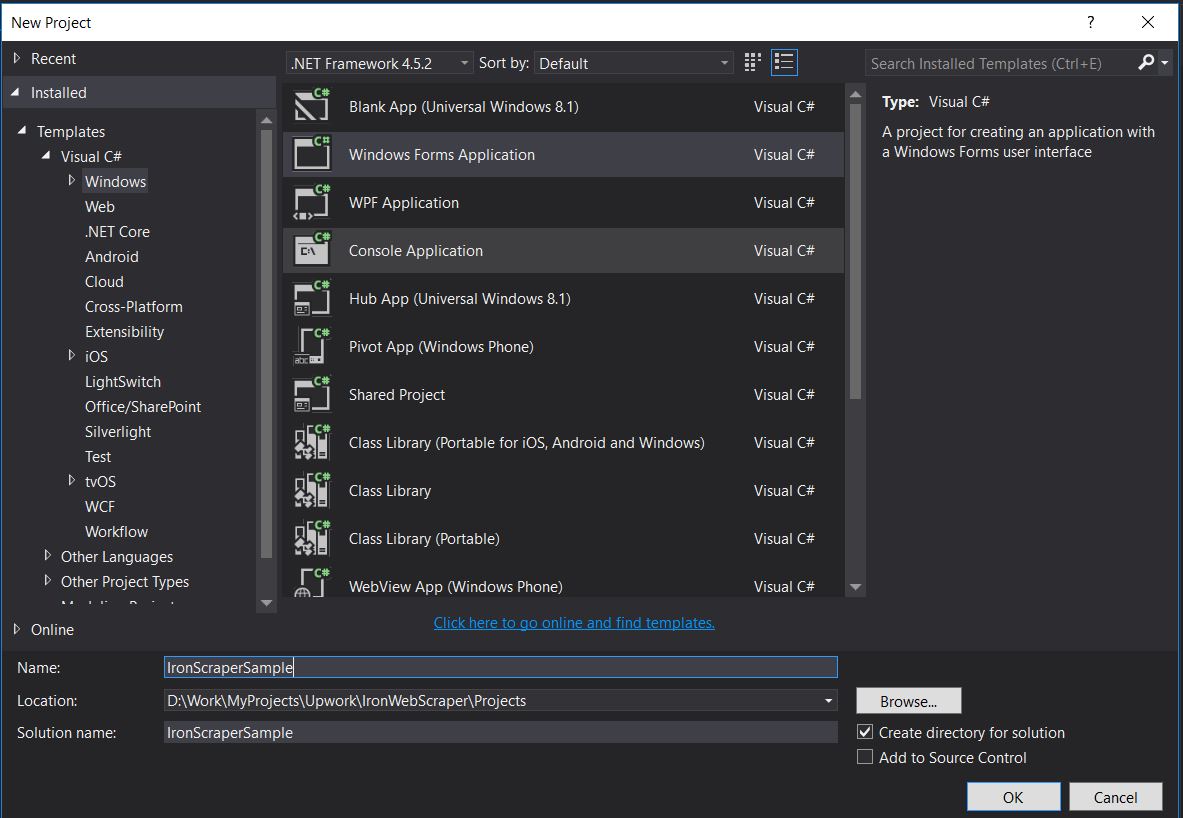
Thực hiện theo các bước sau để tạo Dự án Windows Forms mới:
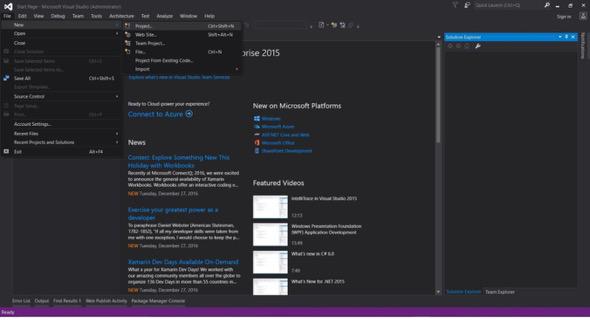
Phòng thu hình ảnh mở
Tệp -> Mới -> Dự án
Từ Mẫu, Chọn ngôn ngữ lập trình (Visual C # hoặc VB) -> Windows -> Ứng dụng Windows Forms
Tên dự án : IronScraperSample location : chọn một vị trí trên Đĩa cứng của bạn
Làm thế nào để tạo một ứng dụng biểu mẫu web?
Bạn nên sử dụng Visual Studio 2013 hoặc cao hơn cho việc này.
Làm theo các bước để tạo Dự án biểu mẫu web Asp.NET mới
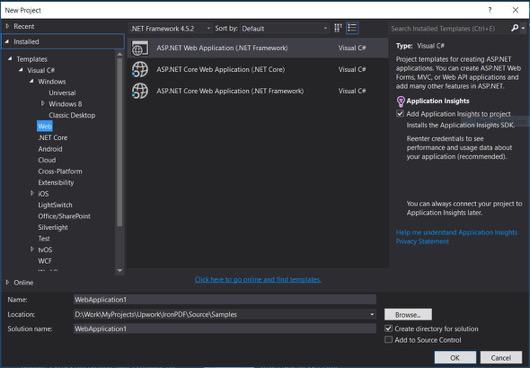
Mở Visual Studio
Tệp -> Mới -> Dự án
Từ Mẫu Chọn ngôn ngữ lập trình (Visual C # hoặc VB) -> Web -> Ứng dụng web ASP.NET (.NET Framework).
Tên dự án : IronScraperSample location : chọn vị trí từ Đĩa cứng của bạn
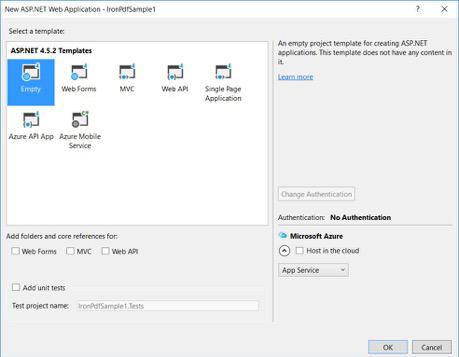
Từ mẫu ASP.NET của bạn
Chọn mẫu trống
Kiểm tra biểu mẫu web
Bây giờ Dự án mẫu ASP.NET Web cơ bản của bạn đã được tạo
Nhấn vào đây để tải về dự án mã poroject mẫu đầy đủ hướng dẫn.
BÀI VIẾT CÙNG CHUYÊN MỤC
Phản Hồi Độc Giả
Một số lưu ý khi bình luận
Mọi bình luận sai nội quy sẽ bị xóa mà không cần báo trước (xem nội quy)
Bấm Thông báo cho tôi bên dưới khung bình luận để nhận thông báo khi admin trả lời
Để bình luận một đoạn code, hãy mã hóa code trước nhé













Một số lưu ý khi bình luận
Mọi bình luận sai nội quy sẽ bị xóa mà không cần báo trước (xem nội quy)
Bấm Thông báo cho tôi bên dưới khung bình luận để nhận thông báo khi admin trả lời
Để bình luận một đoạn code, hãy mã hóa code trước nhé